
国际计算机视觉领域三大顶级会议之一IEEE国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,CVPR) 不久前刚刚落下帷幕,CVPR2024在美国西雅图举办,根据官方数据统计,会议共收到11532篇有效论文投稿,接收2719篇,录用率为23.6%,比例较往年略低。

本文是对发表于CVPR2024 Highlight(Top 10%)论文 《Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images》的解读。论文的共同第一作者为上海交通大学-新加坡国立大学联培博士生黄潮钦(导师:张娅教授、王鑫超助理教授)和硕士研究生蒋傲凡(导师:张娅教授)。论文通讯作者为上海交通大学人工智能学院王延峰教授和新加坡国立大学王鑫超助理教授。
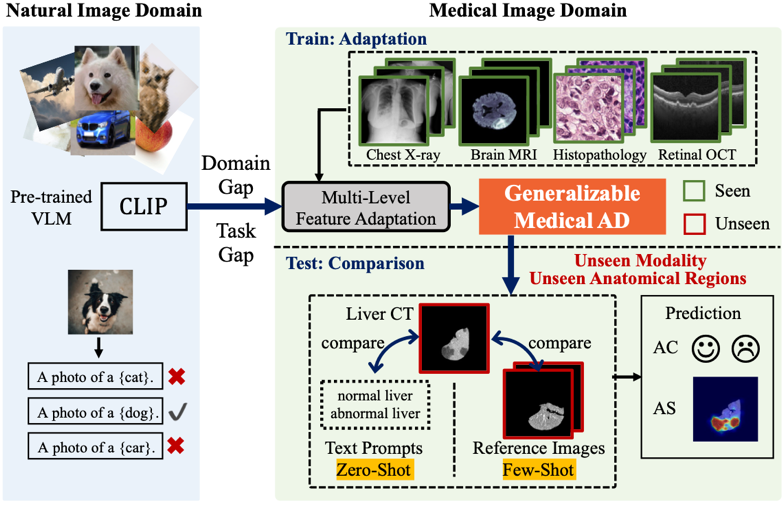
图1. 基于视觉语言模型的零样本/少样本医学影像异常分类和异常分割
简述:论文探索了大规模视觉语言预训练模型面向医学影像异常检测的适配。考虑到自然图像与医学影像之间的领域差异、以及视觉语言预训练与异常检测的任务差异,论文提出了一种新颖的轻量级多层次适应与比较框架,通过在视觉编码器中集成多个残差适配器,利用多层次的像素级视觉语言特征对齐,引导模型从自然图像的物体语义理解转向医学影像的异常识别。适配后的特征在各种医学影像数据类型上表现出更好的泛化能力,能够在零样本场景下有效应对未知的医学成像模态和解剖区域。
论文链接:(点击下方阅读原文)
https://arxiv.org/abs/2403.12570
代码链接:
https://github.com/MediaBrain-SJTU/MVFA-AD
引言
医学异常检测主要用于识别和定位医学影像数据中的异常,是防止误诊和促进早期干预的关键。由于医学图像数据在不同成像模态和解剖区域之间存在巨大差异,这要求模型在各种数据类型上都能表现出色。少样本异常检测方法试图在稀缺的训练数据下实现模型的泛化,但每个新的异常检测任务仍需要轻量级的重新训练(fine-tuning)或分布调整(distribution adjustment)。大规模预训练视觉语言模型(VLMs)为稳健且可泛化的异常检测带来了新的机遇。一个值得注意的尝试是通过精心设计文本提示(prompts),直接利用大规模视觉语言预训练模型CLIP进行异常检测。然而,考虑到自然图像与医学影像之间的领域差异,这些方法在医学影像上的效果不佳,更不用说泛化到未知的成像模态或解剖区域。
将大规模视觉语言预训练模型CLIP适配为医学影像通用的异常检测模型,面临三大挑战:
从自然图像到医学影像存在显著的领域差异(domain gap);
将CLIP模型适配到异常检测面临任务需求的显著转变。CLIP的视觉编码器主要捕捉图像语义,而通用异常检测模型需识别不同语义背景下的异常;
为实现对医学影像的通用性,该异常检测模型需要能泛化到在训练阶段未见过的医学影像成像模态和解剖区域。
论文提出了一个轻量级的多层次视觉特征适配与比较框架,旨在使CLIP模型的特征与医学影像异常检测的需求对齐。该框架结合了适配器调优和多层次的考虑,通过在预训练视觉编码器中集成多个残差适配器实现。利用多层次、像素级的视觉语言特征对齐损失函数引导不同层次的视觉特征逐步增强。这些适配器重新校准模型的关注点,从对象语义转向图像中的异常识别,利用广泛的“正常”或“异常”文本提示。在测试过程中,适配后的视觉特征与文本提示特征进行比较,如果有额外的参考图像特征(few-shot),也会进行比较,从而生成多层次的异常分布图。
所提出的方法在具有挑战性的医学异常检测基准上进行了评估,涵盖了五种不同的医学模态和解剖区域的数据集,包括脑MRI、肝脏CT、视网膜OCT、胸部X光片以及数字病理切片。实验结果表明,该方法在零样本和少样本场景下的异常分类任务中,分别平均提高了6.24%和7.33%AUC,在异常分割任务中分别提高了2.03%和2.37%AUC,显著优于现有最先进的方法。
论文主要贡献总结如下:
提出了一种多层次特征适配框架,这是首次尝试在零样本/少样本场景下将预训练的视觉语言模型用于医学异常检测。
在具有挑战性的医学影像异常检测基准上进行了广泛的实验,展示了其在多种数据模态和解剖区域上的泛化能力。
方法
那么,如何将大规模视觉语言预训练模型CLIP适配到医疗影像异常检测任务呢?
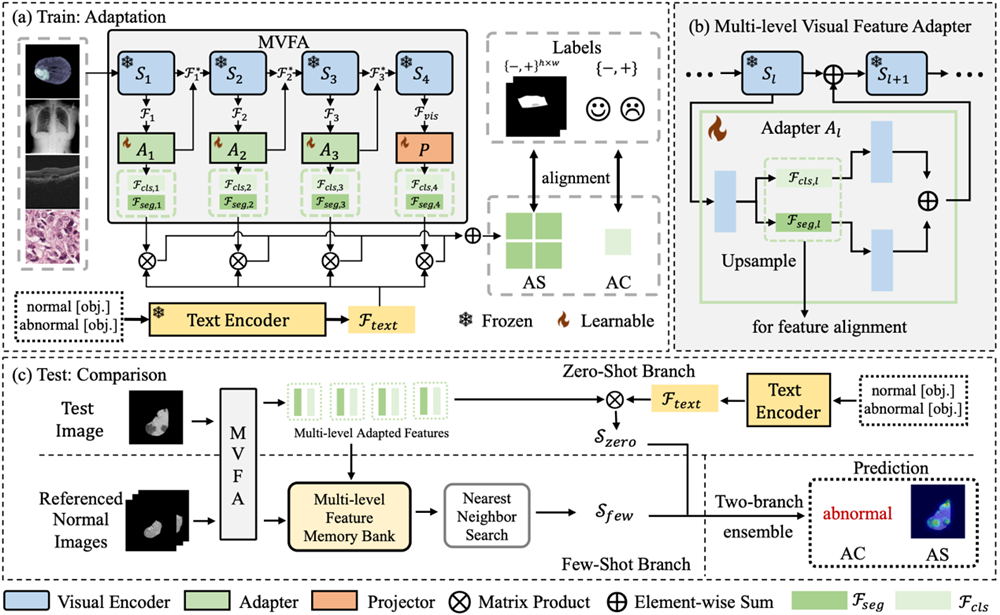
图 2. 基于多层次特征适配的医学影像可泛化异常检测框架
首先,如图2(a)所示,在训练过程中,将大规模视觉语言预训练模型CLIP固定住,只训练轻量级的多层次特征适配网络,用于图像特征和文本特征的对齐。模型的输入由图像-文本对构成,这些图像包含了不同的医学影像模态和人体解剖区域,文本则是以预定义形式,包含图像状态与模版双层次的组合,用于对正常和异常对象进行描述。在状态层面上,我们使用简单而通用的文本来描述正常和异常状态,如“正常脑部MRI图像”和“异常脑部MRI图像”等。模板层面则是对图像形态进行文本描述。通过双层次的组合,得到关于异常和正常两类的文本提示输入。
经过图像和文本编码器得到相应特征后,利用多层特征适配网络,将图像的特征映射到文本空间,并与文本特征以矩阵相乘的方式进行对齐,将多层次的对齐特征进行叠加,用于捕捉不同细粒度的异常形态。最后,根据图像的标签类型(图像级标注或者像素级标注),结合对齐特征计算相应的损失函数,用于监督适配网络的训练。
具体而言,适配网络结构如图2(b)所示,两个分支网络分别用于分类特征和分割特征的适配。适配网络的输出经过残差连接,与输入适配网络的图像特征相加,作为图像编码器下一个block的输入,以此类推,直至图像编码器的最后一个block。特征网络的中间层输出即为视觉适配特征,用于和文本特征进行对齐训练以及测试阶段的特征比较。
在测试阶段,所提出的框架支持零样本与少样本异常检测和分割任务。如图2(c)所示,在零样本场景下,通过将全新模态的视觉适配特征与预定义文本特征进行对齐,将多层次对齐特征组合并放缩至原图大小,即可得到异常检测与分割的结果。在少样本场景下,利用少量目标类别的正常样本,将少量正常样本输入图像编码器得到的视觉适配特征存储进记忆模块。然后将测试图像的视觉适配特征在记忆模块中进行最临近搜索,进一步进行视觉特征之间的比对获得对应的输出,最后将少样本图像比对结果与图像文本对齐结果组合,实现异常检测与分割。
使用所提出的算法对多种医学成像模态和解剖区域图像进行定量测试:
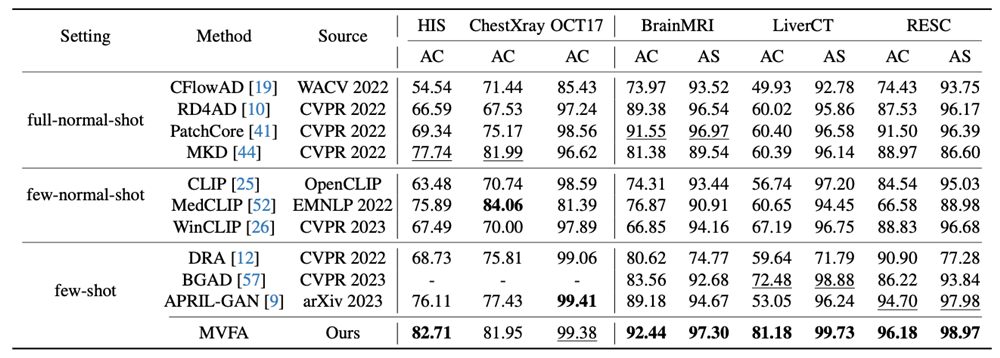
图3. 少样本异常检测结果
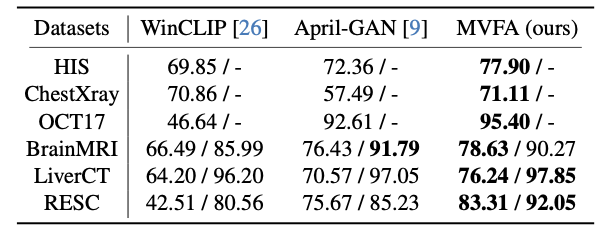
图4. 零样本异常检测结果
在少样本场景(4张正常与异常图片,见图3)和零样本场景(见图4)下,使用脑部MRI、肝脏CT、视网膜OCT、胸部X片以及病理切片图像进行算法验证,并将其与使用相同数据量的最先进方法进行对比。实验结果显示,所提出的算法显著提高了异常检测的准确率,特别是在泛化到全新模态时,效果尤为明显。

图5. 适配网络与映射网络结果比较
除此之外,研究团队还进行了附加实验,以证明所提出的特征适配方法的优异性。将特征适配网络与特征映射网络进行比较(见图5),后者单纯将视觉特征映射至文本空间,不涉及视觉特征的残差链接与协同训练。结果表明,研究团队提出的方法能够更好地学习正常和异常特征的差异,通过适配网络得到的特征能更好地区分正常与异常(见图6)。
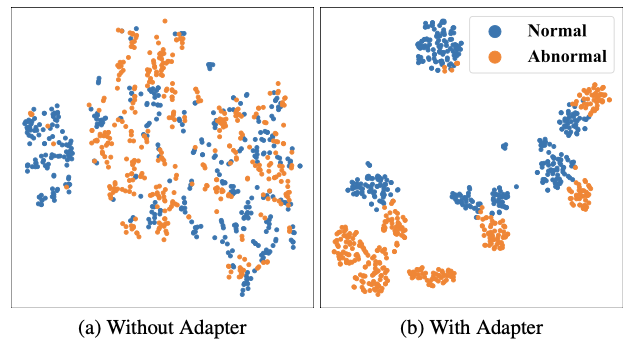
图6. t-SNE特征可视化结果
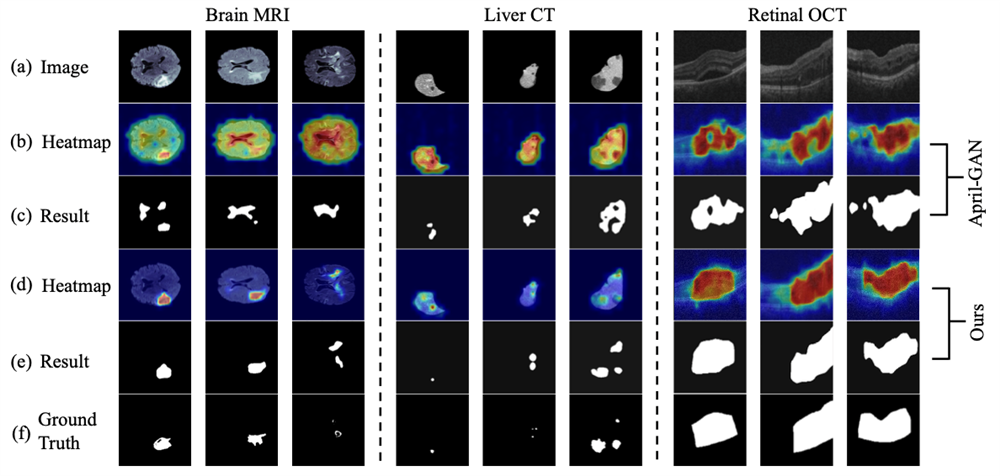
图7. 异常定位可视化结果
最后,研究团队通过可视化方式对目前最先进的方法April-GAN进行比较。实验结果表明,所提出的方法可以更准确地定位出异常区域(见图7)。
总结
在这项研究中,研究团队利用轻量级的多层次特征适配技术,将自然图像领域预训练的视觉语言模型应用于医学影像异常检测任务,成功跨越了领域差异和任务差异,实现了可泛化的医学影像异常检测与定位。无论是在零样本还是少样本的情况下,所提出的方法均展现出远优于最先进异常检测方法的性能。更多方法与实验细节请参照论文原文。

徐汇区办公地址:上海市徐汇区华山路1954号 上海交通大学人工智能学院大楼
闵行区办公地址:上海市闵行区东川路800号老行政楼4、5楼
邮箱:aischool@sjtu.edu.cn 电话:党政综合 021-33687201;科研合作及财务 021-33687203; 人才培养 021-33687205